25th anniversery of my very first testing lesson Rikard Edgren No Comments
On November 2nd 1998 I did my first working day as a tester, 25 years ago.
The first thing I tested was the Swedish version of Internet Explorer 4 Service Pack 2.
We had detailed step-by-step instructions to follow, so it seemed straightforward.
Long-time tester Anders Olsson helped me with my first tests, and on the second test he said:
“And now you perform the same thing as they want, but you do it another way than what is written in the test case.”
“But it says here that I should do it in the same way as in the last test?”
“Yeah yeah, that’s what they write, but if we do it like that we will never find the interesting bugs.”
I said OK, and followed his expertise to vary the way I navigated through the system.
I didn’t understand that this little tip held so many truths about testing:
- testing is a sampling activity
- variation of tests give better test coverage
- unexpected things happen with software
- purpose is more important than something written long ago
- testers have freedom under responsibility
Thank you, Anders!
Regarding free sharing of material Rikard Edgren No Comments
There are lots of people that share material they have created, and make them publically available for anyone.
There are lots of people that share material they have created, and make them publically available for anyone.
Everything is of course not good, but a lot is, and this helps our community to grow, people can build upon each others work, and our combined knowledge increases.
I think most testers do this because they have something to tell, and they want to contribute, but there are also factors like ego and brand-building involved.
But there are rules for how to use other’s materials, especially regarding how to re-use other peoples material.
Besides general copyright rules and common sense, a lot of sites have specific licenses you need to adhere to.
At thetesteye.com, all our publications are licensed under a Creative Commons Attribution-NoDerivs 3.0 Unported License.
This means that you can re-use our material if you give attribution, and if you don’t modify the content (this is to make sure the ideas aren’t misrepresented).
I have experienced several good examples of this, for instance persons asking if they are allowed to translate material (a derivation that needs approval), and when they are done they send a link to the material.
But here are violations I have seen recently of my material:
- no attribution
- attribution in form of “inspired by”, but large chunks of material is copy/paste
- copy/paste of only some parts, taking away the real essence
- copy/paste of material that itself had references, but those references have been removed
- word-by-word translations of large chunks of material
- translations of large chunks of material but with re-phrasing in marketing-style, so it doesn’t really make sense
- re-use of non-public material
There is no point in just re-distributing material (a link is better in that case), so make sure you add something yourself; challenging an idea, developing it further etc.
If you are unsure what is OK or not, I recommend asking a friend and then contacting the author.
If you see something that is re-used incorrectly, I recommend informing the thief about this.
We need to respect the work of others, otherwise people might stop sharing, and the community is at loss.
If testing is easy, you’re doing something wrong Rikard Edgren No Comments
At EuroSTAR 2019 I was co-speaking with Henrik Emilsson on a half-day tutorial on using quality characteristics.
My favorite parts of these intense events are the questions when you don’t know what will happen.
In one of these I ended my answer with “if testing is easy, you’re doing something wrong”.
I remember how happy I was with that sentence, it fitted perfect in the context, and in a sense summarized both how I see testing, and why I love it.
I forgot it while doing the rest of the tutorial, but was reminded when we received the feedback from the tutorial entered by the audience.
The feedback was very good, but one can’t please all (if you are doing that, something is probably wrong…)
One attendant (I don’t know who, and it doesn’t matter) was very negative, and pointed out that when saying “if testing is easy, you’re doing something wrong” we were quite far from good, professional testers.
Now is the time to clarify what I mean, I still think some will disagree with me, but there could be interesting discussions about this (or unconstructive comments if the thoughts about Schools of Testing applies to us).
Testing is difficult
Testing is never complete. We are in the sampling business, and there will always be more tests you could run. This means that you always have to skip an enormous amount of tests that could be run. Many of them are easy to skip, but if you have many really good test ideas, at least I find it often difficult to choose which ones to skip. And after you are quite happy with your test coverage, things are changing. You learn about new things, the surrounding world changes, and suddenly your tests might not be the best anymore. And also, which tests should be run again? How much should your automation maintenence cost?
And cost is always a difficult thing in my experience. Striking the balance of testing cost and value of the information received is not easy, and it is easier to see when you are testing too little than too much.
We are also using serendipity to our advantage; it happens often, but is not predictable and difficult to rely on (but important anyway!)
Testers are humans and make mistakes
If you never make mistakes I am surprised. Mistakes can be small and big, sometimes they are realized and sometimes not. Sometimes mistakes help us find out other important information. There are many reasons for mistakes, but one of them is that we are dealing with complex things, both regarding technology and people. We don’t know everything in advance (if that was the case, testing wouldn’t be needed) and learning is personal, and sometimes “wrong”, but still helpful. Bugs I have missed often fall in the category of “I didn’t know about that”. If something is quite apparent, it could be called a mistake not learning about it, but there are so many things that could be interesting, and it is very difficult to know in advance.
We must also watch out for an environment where making mistakes is bad, because you can end up in situations where people don’t dare doing anything (new), and productivity, creativity, well-being and more disappears.
At the same time it is the humanity, the learning, the mistakes, the creativity that makes software testing important and extremely interesting!
Conclusion
These are reasons I use the “Thank God it’s not easy” heuristic.
If it feels too easy, I have not understood enough.
Of course this isn’t something unique for testing, it probably applies to most areas that deal with complexity and no clearcut answers.
And my thoughts are not new either, so now I have to read Staying with the Trouble by Donna J. Haraway.
thetesteye reunited! the test eye 4 Comments

After some years on different workplaces Henrik, Martin and Rikard have now joined forces at Nordic Medtest, a non-profit company working with digital infrastructure in Swedish healthcare.
We have a lot of important work to do, so there are no guarantees for more frequent updates on this blog, but the chances are at least bigger.
Nonetheless, great fun for us!
Agile Frameworks and the lack of test expertise Martin Jansson 6 Comments
I am a tester and these are my perceptions and reflections on agile concepts.
There are several agile frameworks available for implementation to guide the agile transformation. I have not experienced many frameworks myself, but I have experienced several implementations in an agile organisations. One core theme in the agile movement is that everyone should test and no single person is responsible for quality. This is great! Still, there is a need for guidance and strategy within testing and quality.
If we perceive these frameworks as something to implement and follow blindly, then I think it is doomed to fail. If you instead see them as building blocks, where you take them, tweak them and put them together, you will be less likely to fail. Because each organisation has its own structure, culture, products and people that together create a unique context.
In each agile transformation you also see agile coaches. If these coaches see the framework as a set of rules, instead of a set of guides, then you will probably not be able to tweak how you work with testing, thus being forced to follow the limitations of the agile framework. I have never seen or heard of someone with the capacity to fully know all crafts (software development, hardware development, testing, support, operations, management, and so on) within product development. In that case, how can you coach a whole organisation on all its crafts? I rather see the need for expertise within each of these crafts to guide the agile implementation. But this should not be a problem. Continuous improvement is a natural philosophy of agile, meaning that evolving the implementation of agile and the framework should also be done?
When I study an agile framework such as SAFe, I find lots of good material and good ideas. On the other hand, I do not find much material on testing, culture of testing, test approaches or test strategy. In the bibliography list [see reference 1], I can find one book from Lisa Crispin and Janet Gregory, but that is it. I do not count TDD or ATDD as within the testing craft, rather a development craft. I think SAFe and probably other agile frameworks would benefit from some enrichment of test expertise. I also fail to see any known testers in the contributor list.
What I believe is a common theme in agile is that testing has no special seat at the table of leadership since everyone is expected to work with it. I believe this is wrong. That is why I want to contribute to the subject with my own thoughts, ideas, reflections and experiences on the subject in order to change, add and possibly remove some of their parts. I know that many great testers are struggling with this as well. So instead of saying that the frameworks are crap, I want to tweak them to become better to help in the agile transformation.
References
-
Bibliography of scaled agile framework – http://www.scaledagileframework.com/contributors/
Implication of emphasis on automation in CI Martin Jansson No Comments
Introduction
I would believe, without any evidence, that a majority of the test community and product development companies have matured in their view on testing. At conferences you less frequently see the argumentation that testing is not needed. From my own experience and perceiving the local market, there is often new assignments for testers. Many companies try to hire testers or get in new consulting testers. At least looking back a few years and up until now.
At many companies there is an ever increasing focus and interest in Continuous Deployment. Sadly, I see troublesome strategies for testing in many organisations. Some companies intend to focus fully on automation, even letting go of their so called manual testers. Other companies focus on automation by not accepting testers to actually test and explore. This troubles me. Haven’t testers been involved in the test strategy? Here are few of my pointers, arguments and reasoning.
Automation Snake oil
In 1999 James Bach wrote the article Automation Snake Oil [see reference 1], where he brings up a thoughtful list of arguments and traps to be avoided. Close to 17 years later, we see the same problems. In many cases they have increased because of the Continuous Deployment ideas, but also because of those from Agile development. That is, if you ignore all the new ideas gained in the test domain as well as all research done.
The miracle status of automation is not a new phenomenon, together with the lure of saving time and cost it is seducing. In some cases it will probably be true, but it is not a replacement of thinking people. Instead it could be an enabler for speed and quality.
Testing vs. Checking
In 2009, Michael Bolton wrote an article that clarified a distinction between Testing and Checking. Since then the definition has evolved. The latest article Testing vs. Checking Refined [see reference 2] is the last in the series. Most of the testers I know and that I debate with are aware of this concept and agree with the difference or acknowledge the concept.
If you produce test strategies in a CI-environment that put an emphasis on automation, and if it means mostly doing checking and almost no testing (as in exploration), then you won’t find the unexpected. Good testing include both.
Furthermore when developing a new feature, are you focusing on automating checks fulfilling the acceptance criteria or do you try to find things that have not been considered by the team? If you define the acceptance criteria, then only check if that is fulfilled. It will only enable you to reach a small part of the way toward good quality. You might be really happy how fast it goes to develop and check (not test) the functionality. You might even be happy that you can repeat the same tests over and over. But I guess you failed to run that one little test that would have identified the most valuable thing.
Many years ago a tester came to me with a problem. He said, “We have 16000 automated tests, still our customers have problems and we do not find their problems”. I told him that he might need to change strategy and focus more on exploration. Several years later another tester came to me with the same problem, from the same product and projects. He said, “We have 24000 automated tests, still our customers have problems and we do not find their problems!”. I was a bit surprised that the persistence in following the same strategy for automation while at the same time expecting a different outcome.
In a recent argument with a development manager and Continuous Deployment enthusiast. They explained their strategy and emphasis on automation. They put little focus on testing and exploration. Mostly hiring developers who needed to automate tests (or rather checks). I asked how they do their test design? How do they know what they need to test? One of my arguments was that they limited their test effort based on what could be automated.
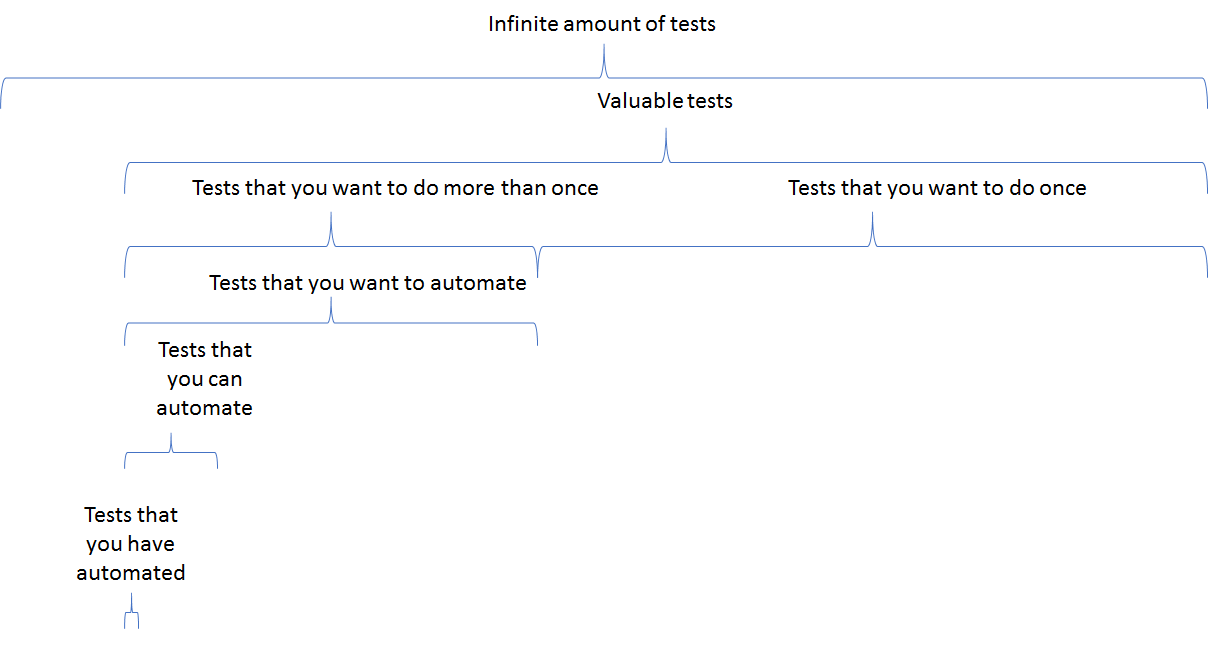
We know that there is an infinite amount of tests. If you have done some research, you have an idea what different stakeholders value and what they are afraid will happen. If that is so, then you have an idea what tests would be valuable to do or which areas you wish to explore. Out of all those tests, you probably only want to run part of these tests only once, where you want to investigate something that might be a problem, learn more about the systems behavior or try a specific, very difficult setup or configuration of the system. This is not something that you would want to automate because it is too costly and it is enough to learn about it just once, as far as you know. There are probably other tests that you want to repeat, but most probably with variation in new dimensions, and do more often. It could be tests that focus on specific risks or functionality that must work at all times. Out of all those that you actually want to test several times, a part of those you plan and want to automate. Out of those that you have planned to automate, only a fraction can be automated. Since automation takes a long time and is difficult, you have probably only automated a small part of those.
If you are a stakeholder, how can you consider this to be ok?
Rikard Edgren visualized the concept of what is important and what you should be in focus in a blog post called “In search of the potato” [see reference 3].
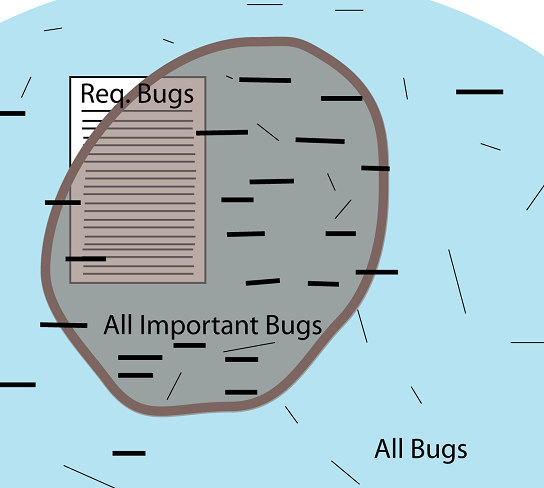
His main points are that the valuable and important is not only in the specification or requirements, you need to go beyond that.
Another explanation around the same concept of the potato is that of mapping the information space by knowns and unknowns.
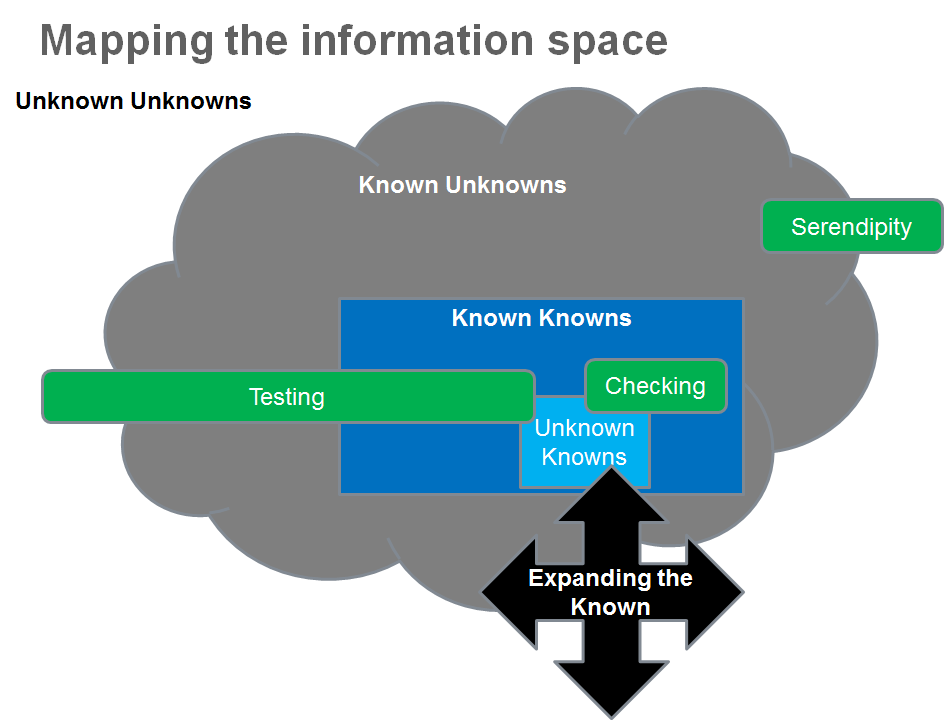
The majority of test automation focus on checking an aspect of the system. You probably want to make repeatable tests on things that you know or think you know, thus the Known Knowns. In making this repeatable checking you will probably save time in finding things that you thought you knew, but that might change over time by evolving the system, thus evaluating the Unknown Knowns. In this area you can specify what you expect, would a correct result would be. With limitation on the Oracle problem, more on that below.
If you are looking beyond the specification and the explicit, you will identify things that you want to explore and want to learn more about. Areas for exploration, specific risks or just an idea you wish to understand. This is the Known Unknowns. You cannot clearly state your expectations before investigating here. You cannot, for the most part, automate the Known Unknowns.
While exploring/testing, while checking or while doing anything with the system, you will find new things that no one so far had thought of, thus things that fall into the Unknown Unknowns. Through serendipity you find something surprisingly valuable. You rarely automate serendipity.
You most probably dwell in the known areas for test automation. Would it be ok to ignore things that are valuable that you do not know of until you have spent enough time testing or exploring?
The Oracle Problem
A problem that is probably unsolvable, is that there are none (or at least very few) perfect or true oracles [see reference 4, 5, 6].
A “True oracle” faithfully reproduces all relevant results for a SUT using independent platform, algorithms, processes, compilers, code, etc. The same values are fed to the SUT and the Oracle for results comparison. The Oracle for an algorithm or subroutine can be straightforward enough for this type of oracle to be considered. The sin() function, for example, can be implemented separately using different algorithms and the results compared to exhaustively test the results (assuming the availability of sufficient machine cycles). For a given test case all values input to the SUT are verified to be “correct” using the Oracle’s separate algorithm. The less the SUT has in common with the Oracle, the more confidence in the correctness of the results (since common hardware, compilers, operating systems, algorithms, etc., may inject errors that effect both the SUT and Oracle the same way). Test cases employing a true oracle are usually limited by available machine time and system resources.
Quote from Douglas Hoffman in A taxonomy of Test Oracles [see reference 6].
Here is a the traditional view of a system under test is like the figure 1 below.
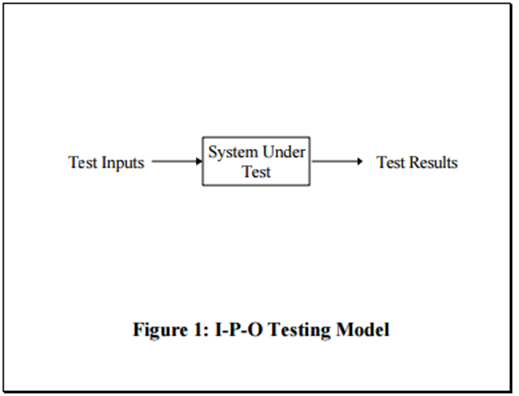
In reality, the situation is much more complex, see figure 2 below.
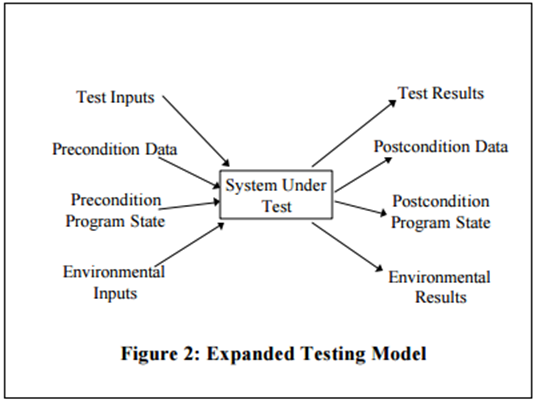
This means that we might have a rough idea about the initial state and the test inputs, but not full control of all surrounding states and inputs. We get a result of a test that can only give an indication that something is somewhat right or correct. The thing we check can be correct, but everything around it that we do not check or verify can be utterly wrong.
So when we are saying that we want to automate everything, we are also saying that we put our trust in something that is lacking perfect oracles.
With this in mind, do we want our end-users to get a system that could work sometimes?
Spec Checking and Bug Blindness
In an article from 2011, Ian McCowatt expresses his view on A Universe of behavior connected to Needed, Implemented and Specified based on the book Software Testing: A Craftsman’s Approach” by Paul Jorgensen.
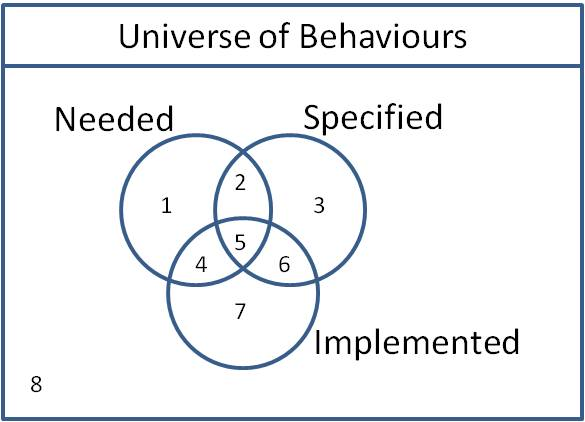
For automation, I would expect that focus would be on area 5 and 6. But what about unimplemented specifications in area 2 and 3? Or unfullfilled needs in area 1 and 2? Or unexpected behaviors in area 4 and 7? Partly undesired behaviors will be covered in area 6 and 7, but enough?
As a stakeholders, do you think it is ok to limit the overall test effort to where automation is possible?
Concluding thoughts
It seems like we have been repeating the same things for a long time. This article is for those of you who are still fighting battles against strategies for testing which state automate everything.
References
- Test Automation Snake Oil, by James Bach – http://www.satisfice.com/articles/test_automation_snake_oil.pdf
- Testing and Checking Refined, by James Bach & Michael Bolton – http://www.satisfice.com/blog/archives/856
- In search of the potato, by Rikard Edgren – http://thetesteye.com/blog/2009/12/in-search-of-the-potato/
- The Oracle Problem and the Teaching of Software Testing, by Cem Kaner – http://kaner.com/?p=190
- On testing nontestable programs, by ELAINE J. WEYUKER – http://www.testingeducation.org/BBST/foundations/Weyuker_ontestingnontestable.pdf
- A Taxonomy for Test Oracles, by Douglass Hoffman – http://www.softwarequalitymethods.com/Papers/OracleTax.pdf
- Spec Checking and Bug Blindness, by Ian McCowatt – http://exploringuncertainty.com/blog/archives/253
System definition and confidence in the system Martin Jansson No Comments
As a tester, part of your mission should be to inform your stakeholders about issues that might threaten the value of the system/solution. But what if you as a tester do not know the boundary of the system? What if you base your confidence of the result of your testing on a fraction of what you should be testing? What if you do not know how or when the system/solution is changed? If you lack this kind of control, how can you say that you have confidence in the result of your testing?
These questions are related to testability. If the platform we base our knowledge on is in fluctuation, then how can we know that anything of what we have learnt is correct?
An example. In a project I worked on, the end-to-end solution was extremely big, consisting of many sub systems. The solution was updated by many different actors, some doing it manually and some doing it with continuous deployment. The bigger solution was changed often and in some cases without the awareness of the other organisations. The end-to-end testers sometimes performed a test that took a fair amount of time. Quite often, they started one test and during that time the solution was updated or changed with new components or sub systems. It was difficult to get any kind of determinism in the result of testing. When writing the result of a test, you probably want to state which version of the solution you were using at the time. But how do you refer to the solution and its version in a situation like this?
When you test a system and document the result of your tests you need to be able to refer to that system in one way or another. If the system is changed continuously, you somehow need to know when it is changed, what and where the change is as well. If you do not know what and where there are changes, it will make it harder for you to plan the scope of your testing. If you do not know when, it is difficult to trust the result of your tests.
One way of identifying your system is to first identify what the system consists of. Considering the boundary of the system and what is included. Should you include configuration of the environment as part of the system? I would. Still, there are no perfect oracles. You will only be able to define the system to certain extent.
|
Sub systems |
System version 1.0 |
System version 1.1 |
System version 1.2 |
|
component 1 version |
1.0 |
1.1 |
1.1 |
|
component 2 version |
1.0 |
1.0 |
1.0 |
|
component 3 version |
1.0 |
1.0 |
1.1 |
As you define parts or components of the system, you can also determine when each are changed. The sum of those components are the system and its version. I am sure there are many ways to do this. Whatever method you choose, you need to be able to refer to what it is.
I think it is extremely important that you do anything you can to explore what the system is and what possible boundaries it could have. You need many and different views of the system, creating many models and abstractions. In the book “Explore IT!”, Elizabeth Hendrickson writes about identifying the eco system and performing recon missions to charter the terrain, which is an excellent way of describing it. When talking about test coverage you need to be able to connect that to a model or a map of the system. By doing that you also show what you know are coverable areas. Another way of finding out what the system is using the heuristic strategy model, by James Bach, and specifically exploring Product Elements. Something that I have experienced is that when you post and visualize the models of the system for everyone to see, you will immediately start to gain feedback about them from your co-workers. Very often, there are parts missing or dependencies not shown.
If one of your missions as a tester is to inform stakeholders to make sound decisions, then consider if you know enough of the system to be able to recommend a release to customer or not. Consider what you are referring to when you talk about test coverage and if your view of the system is enough.
References
- Explore It! by Elisabeth Hendrickson – https://pragprog.com/book/ehxta/explore-it
-
Heuristic Test Strategy Model by James Bach – http://www.satisfice.com/tools/htsm.pdf
-
The Oracle Problem – http://kaner.com/?p=190
-
A Taxonomy for Test Oracles by Douglas Hoffman – http://www.softwarequalitymethods.com/Papers/OracleTax.pdf
Scripting Your Test Data Rikard Edgren 3 Comments
Sometimes I wonder if testers know how easy it is to script your own variations of test data.
I prefer Ruby, and you can download this example that I will tell you about.
I was testing healthcare data and wanted to see what the performance was for larger quantities of data. We had a mock service, and the data to put there was easy to create with a script.
For the “diagnosis” area, I had an Excel sheet with the 12441 possible diagnosis codes according to ICD-10-SE. I couldn’t resist creating a test patient that had all of these diagnosis.
This will never, never happen in reality, and does not add value to the performance tests, but I did it anyway, it was fun and fast.
After the performance tests where completed I continued using the test data I had created.
It is a kind of background complexity that isn’t really necessary, but doesn’t cost a lot, and might help you discover new things. And of course it did also this time (hey, I chose the example).
When testing search functionality I saw behaviors I hadn’t seen with the more simplistic data I had elsewhere. The large variety of diagnosis names gave possibilities for the search function to go wrong.
If you aren’t already doing stuff like this, feel free to edit the Ruby script to match your needs (most data files are text in some kind and can be scripted in this way) to create more variety to your test data.
Quite often, your tests aren’t a lot better than your test data.
Five Tricky Things With Testing Rikard Edgren 5 Comments
I went to SAST Väst Gothenburg today to hold a presentation that can be translated to something like “Five Tricky Things With Testing”. It was a very nice day, and I met old and new friends. Plus an opportunity to write the first blog post in a long time, so here is a very condensed version:
1. People don’t understand testing, but still have opinions. They see it as a cost, without considering the value.
Remedy: Discuss information needs, important stuff testing can help you know.
2. Psychologically hard. The more problems you find, the longer it will take to get finished.
Remedy: Stress the long-term, for yourself and for others.
3. You are never finished. There is always more to test, but you have to stop.
Remedy: Talk more to colleagues, perform richer testing.
4. Tacit knowledge. It is extremely rare that you can write down how to test, and good testing will follow.
Remedy: More contact of the third degree.
5. There are needs, but less money.
Remedy: Talk about testing’s value with the right words, and deliver value with small effort, not only with bugs.
Summary: Make sure you provide value with your testing, also for the sake of the testing community,
There were very good questions, including one very difficult:
How do you make sure the information reaches the ones who should get it?
Answer: For people close to you, it is not so difficult; talk about which information to report and how from the beginning. I don’t like templates, so I usually make a new template for each project, and ask if it has the right information in it.
But I guess you mean people more far away, and especially if they are higher in the hierarchy this can be very difficult. It might be people you aren’t “allowed” to talk to, and you are not invited to the meetings.
One trick I have tried is to report in a spread-worthy format, meaning that it is very easy to copy and paste the essence so your words reach participants you don’t talk to.
Better answers is up to you to find for your context.
Serendipity Questions Rikard Edgren No Comments
This Tuesday I held a EuroSTAR webinar: Good Testers are Often Lucky – using serendipity in software testing (about how to increase the chances of finding valuable things we weren’t looking for)
Slide notes and recording are available.
I got many good questions, and wanted to answer a few of them here:
How can we advocate for serendipity when managers want to cut costs?
Well, the “small-scale serendipity” actually doesn’t cost anything. It just requires a tester to be ready for unexpected findings, and sometimes spend 20 seconds looking at a second place. The cost appears when investigating important problems, but in that case, I would guess it is worth it (never seeing any problems or doing no testing at all would be the lowest cost…)
I also know that many testing efforts involve running the same types of tests over and over again. When you know these tests won’t find new information, maybe it is time to skip them sometimes and do something rather different?
Do you have issues finding the root of the problem considering you are doing many variations?
If it is a product I know well, I don’t have problems reproducing and isolating. But if it is a rather new product it can be more difficult, but I would rather see these problems and communicate what I know, than not see them at all!
To take more detailed notes than normally, or to use a tool like Problem Steps Recorder (psr on Windows) can help if you expect this to happen.
Is there any common field for automated testing and serendipity?
Yes!
It is easy to think that automation is a computeresque thing without a lot of manual involvement and tinkering with the product. But in my experience, you interact a lot with the product while learning and creating your tests. And I make mistakes that can discover problems with the product’s error handling.
I know this combination of coding and exploratory testing happens a lot, but it is not very elaborated in the literature (but the recent automation paper by Bach/Bolton have good examples on this.)
Another example of automation and serendipity is that you combine human observations while the tests are running. A person can notice patterns or anomalies, or maybe see what the users perception is when the software is occupied with a lot of other things.
Computers are marvellous, but they suck at serendipity.